
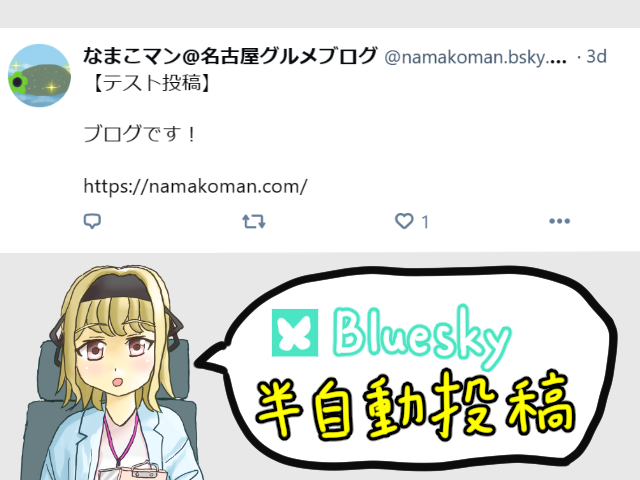
ブログ以外に、SNSでも活動しています。そして、様々なSNSで様々な方と繋がれています。せっかくなので、SNSのフォロワーさんにもブログをアピールしていきたいです。
2024年2月に、これまで紹介制だった短文SNS「Bluesky」が一般開放されました。SNSの新興勢力ということで、新規ユーザー同士の交流が特に盛んに行われている印象です。気付けば僕のアカウントのフォロワー数も増えてきました。しかも、InstagramやThreadsとはまた違った層のユーザーさんと繋がれています。
こうなれば、是非ともBlueskyのフォロワーさんにもブログをアピールしていきたいところです!
かつてのTwitterでは、ワードプレスの「Revive Old Posts」というプラグインを使えば簡単に投稿記事へのリンクを自動投稿することができましたが、本記事投稿時(2024年4月)現在、Blueskyに対応したプラグインはまだありません。ですが、BlueskyへはAPIを使ってコマンドライン経由で投稿が可能です。
そこで、なけなしのPythonの知識を絞り出し、ブログの過去記事へのリンクをBlueskyに半自動的に投稿するスクリプトを組んでみました。備忘録をまとめておきます。
0.モチベーション
・今日以降の任意の日の決まった時間に、Blueskyにブログ過去記事へのリンクを含んだポストを自動投稿したい。
手動で過去記事宣伝ポストをできるならそれで良いのですが、仕事や移動中などで必ずしもできるとは限りません。なので、予約投稿のような感じで決まった時間に自動的に宣伝ポストを投稿してくれるとありがたいです。
・サムネイル画像を含んだリンクカード付きのポストを投稿したい。
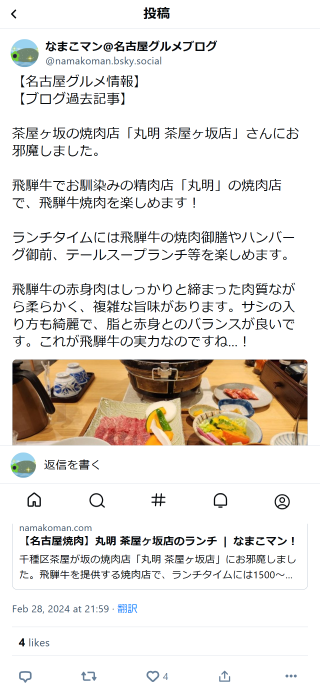
ブログへの誘導には、文字だけのポストよりも、記事のサムネイル画像を含んだリンクカードのあるポストのほうが効果的と考えられます。
1.準備
スクリプトを書き始める前に自力で以下のファイルを準備しておきます。
・記事URLをまとめたCSVファイル
・自動投稿ポストの本文を記入したテキストファイル(任意)
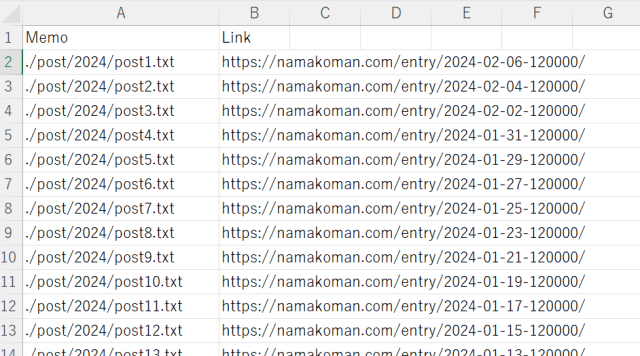
Blueskyに投稿したい過去記事のURL(と後述の本文用テキストファイルのパス)をまとめたCSVファイルを準備しておきます。これはまあ、何らかの手段で集めてください(笑) 僕は「XML Sitemap Generator for Google」というプラグインで生成したサイトマップから記事URLを取得しています。そもそもこのプラグインはワードプレスの記事をGoogle検索にインデックスしたいときにはほぼ必須級のものなので、ワードプレスユーザーなら入れている方のほうが多いのではないかと思います。

これは任意ですが、もし投稿ごとに異なる文章を自動投稿したい場合は、ポスト本文を記載したテキストファイルも記事ごとに用意しておきましょう。当記事のスクリプトでは本文テキストファイルを用意しています。
2.スクリプト解説
Pythonのバージョンは3.10.6、環境はJupyter Lab4.1.2にて実行しています。
必要パッケージをインストール
!pip install atproto
!pip install requests
!pip install bs4
!pip install pytz
!pip install pandas
!pip install numpyJupyter Labなのでシェルコマンドの「!」をつけて必要パッケージをインストールしています。
パッケージ、モジュール読み込み
from bs4 import BeautifulSoup
import requests
import io
from atproto import Client
from atproto import models
from atproto import client_utils
import datetime
import time
import pytz
import pandas as pd
import numpy as np先ほどインストールしたパッケージ以外にも、io、datetime、timeを読み込んでいます。
リンクカード取得関数
def get_title_and_description(url:str):
title : str = ''
description : str = ''
thumbnail : str = ''
response = None
try:
# requestsで対象のURLに対してGET
response = requests.get(url, timeout=60)
except:
return '', '', ''
if response.status_code != 200:
return '', '', ''
# responseに含まれるテキストデータを、HTMLパーサで処理
soup = BeautifulSoup(response.text, 'html.parser')
# titleタグ内のテキストを取得
result = soup.find('title')
if result != None:
title = result.text
# metaタグdescription内のテキストを取得
result = soup.find('meta', attrs={'name': 'description'})
if result != None:
description = result.get('content')
# metaからサムネイルを取得
result = soup.find('meta', attrs={'name': 'thumbnail'})
if result != None:
thumbnail = result.get('content')
# タプルでまとめて返す
return title, description, thumbnailまずはリンクカードを生成するために、ブログ記事から記事タイトル、メタディスクリプション、サムネイル画像リンクを取得する関数を定義します。この関数は参考リンク2つ目のMimaki SiONさんの記事を参考に、サムネイル画像リンクを取得する処理を追加しています。
ログイン
client = Client()
client.login('ユーザー名', 'パスワード')ここでBlueskyにログインします。client.login()メソッドの引数はそれぞれ自分のBlueskyユーザー名(○○.bsky.social)とパスワードを入力します。
リンク,ポスト内容読み込み
linpos = pd.read_csv("./linpos.csv")最初に作成したCSVファイル(ここでは『linpos.csv』という名前にしています)を読み込みます。ファイルパスは各々の環境に合わせて書き換えてください。
日付入力
while True:
try:
d = input("日付をY-M-Dの形式で入力(\"q\"で終了):")
if d == "q":
break
else:
today = datetime.datetime.strptime(str(d) + "+0900" ,'%Y-%m-%d%z')
diff = today - datetime.datetime.now(pytz.timezone("Asia/Tokyo"))
if diff.days >= -1:
break
else:
print("今日または明日以降の日付を入力してください。")
except:
print("日付をY-M-Dの形式で入力してください。")ここでポストを投稿する日付を入力します。任意の日に投稿できるように、投稿日はinputで渡す形式にしました。
入力した投稿日は日本時間に変換され、同じく日本時間に変換されたdatetime.now()との差分を求めます。一応、このスクリプトを走らせている当日もしくはそれ以降の日付を入力しなければ、ループから抜けられないような仕様になっています。
ただ、inputを使っているから自動化できないと言っても過言ではないので、ここはもっとうまいやり方がある気がします…!
CSVからランダムで記事を8つ取得
rng = np.random.default_rng()
linpos_selected = linpos.iloc[rng.choice(len(linpos.index), 8, replace = False), :]
print(linpos_selected)
# Memo Link
#0 ./post/2024/post1.txt https://namakoman.com/2024-02-06-120000/
#2 ./post/2024/post3.txt https://namakoman.com/2024-02-02-120000/
#10 ./post/2024/post11.txt https://namakoman.com/2024-01-17-120000/
#15 ./post/2024/post16.txt https://namakoman.com/2024-01-07-120000/
#16 ./post/2024/post17.txt https://namakoman.com/2024-01-05-120000/
#11 ./post/2024/post12.txt https://namakoman.com/2024-01-15-120000/
#4 ./post/2024/post5.txt https://namakoman.com/2024-01-29-120000/
#1 ./post/2024/post2.txt https://namakoman.com/2024-02-04-120000/先ほどデータフレームとして読み込んだCSVから、重ならないようにランダムで8行(=8記事)選び、新たなデータフレーム「linpos_selected」を生成します。
自動ポスト時刻設定
posttime = ["08:00", "10:00", "12:00", "14:00", "16:00", "18:00", "20:00", "22:00"]自動投稿の時刻を格納したリストを作成します。
今回は8時~22時の間に2時間ごとに計8回投稿するようにしました。だから先ほどのlinpos_selectedデータフレームもランダムに8行選んで生成したというわけです。
自動ポスト
for i in range(8):
#タイトル等取得
title, description, thumbnail = get_title_and_description(linpos_selected.iloc[i, 1])
#画像アップロード(画像をバイナリに変換しアップロード)
response = requests.get(thumbnail)
img = io.BytesIO(response.content)
upload = client.com.atproto.repo.upload_blob(img)
#リンクカード作成
embed_external = models.AppBskyEmbedExternal.Main(
external = models.AppBskyEmbedExternal.External(
title = title,
description = description,
thumb = upload.blob,
uri = linpos_selected.iloc[i, 1]
)
)
#本文データよりポスト取得
with open(linpos_selected.iloc[i, 0],encoding="utf-8") as f:
post = f.read()
#投稿
start_time = datetime.datetime.strptime(d + posttime[i] + "+0900", '%Y-%m-%d%H:%M%z')
time_second = (start_time - datetime.datetime.now(pytz.timezone('Asia/Tokyo')))
if time_second.days < 0:
client.send_post(post, embed = embed_external)
print(f"{d} ポストを投稿しました。")
else:
time.sleep(time_second.seconds)
client.send_post(post, embed = embed_external)
print(f"{d} {posttime[i]} ポストを投稿しました。")
#2024-2-28 08:00 ポストを投稿しました。
#2024-2-28 10:00 ポストを投稿しました。
#2024-2-28 12:00 ポストを投稿しました。
#2024-2-28 14:00 ポストを投稿しました。
#2024-2-28 16:00 ポストを投稿しました。
#2024-2-28 18:00 ポストを投稿しました。
#2024-2-28 20:00 ポストを投稿しました。
#2024-2-28 22:00 ポストを投稿しました。ここでようやく自動ポストを始めます。
最初に定義したget_title_and_description関数で、linpos_selectedデータフレームの2列目(記事URL)より記事タイトル、メタディスクリプション、サムネイル画像リンクを取得します。そして、取得したサムネイル画像リンクをBlueskyにアップロードし、記事タイトル、メタディスクリプション、サムネイル画像から画像付きリンクカードを生成します。
続いて、linpos_selectedデータフレームの1列目(本文テキストファイルのパス)をwith open()で読み込みます(Windows環境なので文字コードをUTF-8に設定しています)。
最後に、設定した投稿日と、現在の時刻との差分を秒数で求め、その秒数が経過した後にclient.send_post()メソッドでBlueskyにポストを投稿します。ポスト本文は第1引数で受け取ります。このコードではwith open()で読み込んだ本文テキストファイルの内容を渡しています。embed引数にリンクカードオブジェクトを渡します。
ところで、このスクリプトでは記事の投稿時刻を8時から22時までの2時間ごとに指定していますが、仮に朝寝坊して朝9時にスクリプトを動かしたとします。その場合、8時に投稿されるはずだったポストはスクリプトを動かしてから即座に投稿される設定になっています。
3.おわりに
これで任意の日にブログ過去記事へのリンクを自動投稿できるスクリプトを組めました。ただしこのスクリプトにも当然ながら欠点があって、それは当然ながらスクリプトを走らせている間ずっとパソコンを点けっぱなしにしておかなければならないことです(笑)
time.sleepやscheduleで定期実行を実装するのって、サーバーのような常時起動しているマシンが対象なのでしょうか…?そういうこともあまりよくわかっていないレベルの男がこの記事を書いています。そもそも最初はGoogle colab環境での実行を考えていましたが、ずっと操作していないとセッションが切れちゃうのをすっかり忘れていましたよ…(え)
このスクリプトを走らせて、Blueskyに定期的にブログ過去記事を投稿するようになってから、Blueskyからブログへのアクセスが増えた… かは微妙ですが、最近合格した「Python3エンジニア認定データ分析試験」の知識を活かすことができましたし、勉強にもなりました。
この備忘録が、同じようなことを試みているどなたかの参考になれば幸いです。
最後に、参考にさせていただいた先人の試行の数々に感謝します!そして、有識者の皆様からの「ここはこうしたら良いのではないか」というご提案もお待ちしております。
4.参考リンク



5.次は自動化…?
やはりパソコン点けっぱなしでのスクリプト稼働は不意のWindows Updateで終わってしまう可能性があるため、何らかの手段で自動化したいところです。
でも身近にサーバーが無い…
このブログ用にレンタルしているエックスサーバーじゃダメなんですか?
あっ!!その手があった!!!
次はこのスクリプトを、レンタルサーバー上で走らせる、何らかの手段を考えたいと思います…!
自動化しました↓


コメント